ChatGPT
ChatGPT一夜之间成了热门,好兄弟问我,能搞不?那研究一下吧。
首先回答一个问题:ChatGPT做了什么事?这其实就是一个对话系统,只不过被传得有点神。号称能够改代码,写小说,甚至查BUG。但其本质,也就是使用强化学习模型整了一个对话系统出来。底层是GPT的逻辑。所以,这个神话需要被打破一下。
那么ChatGPT是怎么做的呢?它是孪生兄弟InstructGPT的改进版,核心要素在于RLHF,也就是Reinforcement learning from human Feedback,需要人工反馈的参与。RLHF是使用了一个reward预测器生成reward参与到RL的训练过程中。这个Reward预测器可以接收人工反馈并更新,从而调整模型。
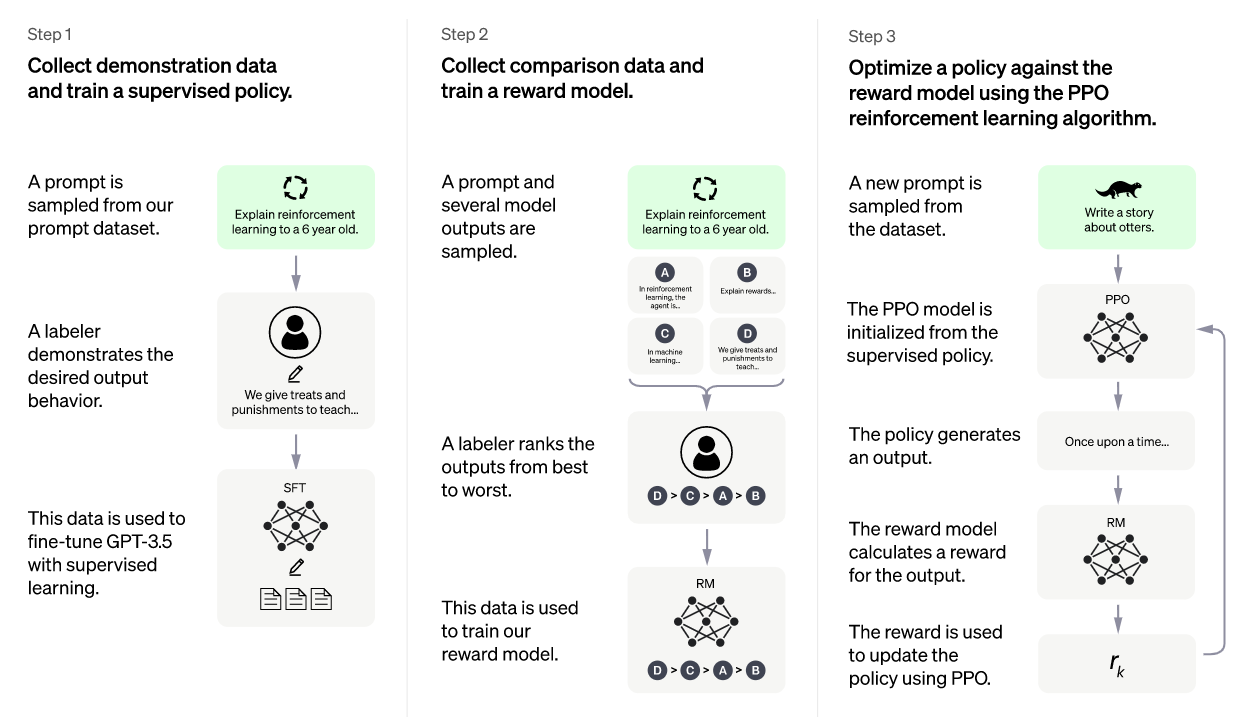
主要的三个步骤:
-
使用语料训练一个GPT模型,这里的语料差异,就是ChatGPT与InstructGPT的差异。但都使用了人工介入的方式获取语料。
-
排序GPT生成的结果,并训练一个Reward预测模型。这里的排序也需要人工参与。
-
最后放到PPO RL训练。使用前面的GPT与reward,就可以训练出一个RL模型。
前两步的主观因素特别大,所以所说openAI控制了标注人员的数量。
附上两个参考文献: